정말 쉬운 연관규칙 알고리즘
1. 들어가며 연관규칙은 장바구니 분석(market basket analysis)이라고도 하는데, 원래 마트의 거래 데이터(transaction data)를 분석하고자 하는 필요성에서 활발하게 탐구되었다. 다른 많은 머신러닝 알
diseny.tistory.com
1. 들어가며
연관분석에 대한 이론을 배웠다면 이제 실습을 해보자. 먼저 관련 패키지와 실습 데이터를 로드한다.
library(arules)
groceries <- read.transactions("groceries.csv", sep = ",")
summary(groceries)
실행하면 다음과 같은 결과가 나오는데 중요한 의미를 이미지로 캡쳐 했다.

2. 데이터 탐색
처음 다섯개의 거래와 가장 거래가 빈번한 품목을 보자
inspect(groceries[1:5])
itemFrequency(groceries[ , 1:3])
결과는 아래 그림과 같다.

10% 이상의 지지도를 갖는 제품을 시각화해보자.
itemFrequencyPlot(groceries, support=0.1)
itemFrequencyPlot(groceries, topN=20)

3. 연관규칙 찾기
groceryrules <- apriori(groceries, parameter = list(support =
0.006, confidence = 0.25, minlen = 2))
# 처음 3개 규칙 확인
inspect(groceryrules[1:3])
ㆍdata는 거래 데이터를 포함하는 희귀 매트릭스이다
ㆍsupport는 최소 지지도 수
ㆍconfidence는 최소 신뢰도 값
ㆍminlen은 최소 규칙 수
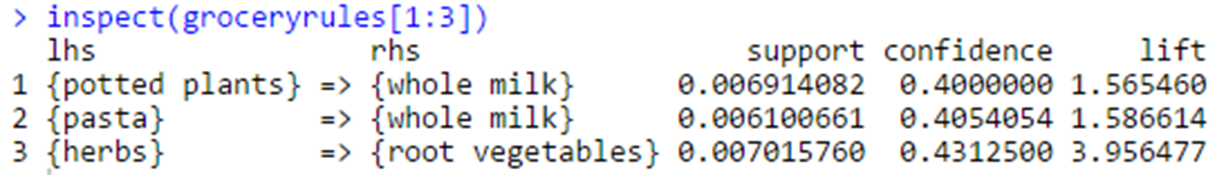
출력 결과에 대한 해석은 다음과 같다.
1.화분 식물을 사면 전유도 산다
2.전체 거래 중에 화분 식물과 전유를 같이 산 비율은 0.6%
3.화분 식물을 산 사람 중 40%가 전유를 같이 산다
4.그냥 전유를 산 사람과 연관 규칙에 의해 전유를 산 사람의 비율
# lift로 규칙 정렬
inspect(sort(groceryrules, by = "lift")[1:5])
# 딸기류 아이템을 포함하는 규칙의 부분 규칙 찾기
berryrules <- subset(groceryrules, items %in% "berries")
inspect(berryrules)

반응형
'R_데이터 분석 기술' 카테고리의 다른 글
| 편상관계수(partial correlation) 구하기 (0) | 2022.06.19 |
|---|---|
| 리커트(likert) 척도 데이터 분석 (0) | 2022.06.11 |
| R 확인적 요인분석(CFA) (0) | 2022.05.13 |
| R 크론바흐 알파 값 계산 (0) | 2022.05.13 |
| R을 이용한 t-test와 효과 크기 계산 (0) | 2022.05.04 |
| R 랜덤포레스트(randomforest) (0) | 2022.05.03 |
| R_의사결정나무 분석(rpart) (0) | 2022.05.02 |




댓글