1. 인공지능, 머신러닝, 딥러닝은 어떤 관계일까
인터넷이나 도서 등에서 찾아보면 다음 그림처럼 “딥러닝 < 머신러닝 < 인공지능”의 포함관계로 연결되는 위계 구조를 볼 수 있습니다. 즉 처음에 인공지능 개념이 있었고 그다음에 머신러닝 개념이 생겨났고 제일 마지막에 딥러닝이 탄생했음을 알 수 있죠.
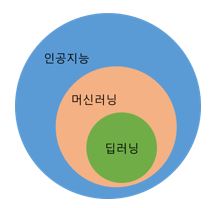
그런데 이런 포함관계를 조금 다르게 생각해봅시다. 인공지능을 구현하는 방법에는 머신러닝이 아닌 다른 개념도 있고 마찬가지로 머신러닝에는 딥러닝이 속하지 않은 다양한 영역과 방법이 있다는 이야기가 되겠죠? 따라서 이 글에서는 주인공인 ‘딥러닝’ 외의 조연들을 먼저 짧게 소개하겠습니다. 비교를 통해 딥러닝의 본 모습을 더 선명하게 드러낼 수 있기 때문입니다.
2. 초기의 인공지능 연구, 컴퓨터에 지능을 심다
우리가 지능이라고 뭉뚱그려 부르는 능력은 여러 범주로 나뉩니다. 숫자 계산을 하는 능력도 지능이지만 이 능력은 일차적인 수준이고, 이미 알고 있는 하나의 사실을 바탕으로 어떠한 판단을 내릴 수 있는 추론 능력이야말로 인간 지능의 핵심입니다. 그런데 인공지능의 시초라고 여겨지는 1950년대 다트머스 대학에 모인 당시의 연구자들은 인간의 다양한 지적 능력에 대해 깊이 생각하지 않은 듯합니다. 그랬기에 인공지능을 만들겠다는 저 무모한 항해를 시작했을테니까요.
결론부터 말하면 컴퓨터는 최근까지도 숫자 계산을 빨리 할 수 있는 기계였을 뿐입니다. 키보드에서 마우스로, 터치패드로 인터페이스가 바뀌었다거나 동영상을 보면서 문서 작업을 할 수 있게 되었어도 이 모든 것은 본질적으로는 숫자 계산을 더 빨리하게 된 것일 뿐이죠. 적어도 인공지능이라는 명칭을 붙이려면 컴퓨터가 사람처럼 이미 알고 있는 X를 통해 미지의 Y를 이끌어낼 수 있는 추론 능력을 갖추어야 합니다.
그리고 추론을 하거나 판단을 하는 능력을 컴퓨터에게 심어주려면 먼저 어떻게 추론, 판단을 하는지 그 내부 과정을 알아야 합니다. 하지만 아직도 사람의 뇌가 어떻게 추론 능력을 발달시키는지 확실하게 모릅니다. 이제 겨우 신경세포들이 서로 전기 신호를 주고 받으면서 뭔가가 작동한다는 정도만 알 뿐입니다. 그러니 그런 사실조차 몰랐던 당시의 연구자들이 컴퓨터에게 추론 능력을 심어주기란 애초부터 불가능한 일이었죠.
3. 추론을 할 수 없는 컴퓨터
그러다 보니 초기의 인공지능 연구자들은 의학, 법률 등의 전문적인 지식을 컴퓨터에 저장하고 여러 조건문의 조합으로 특정한 결론을 이끌어내는 방식을 생각합니다. 예를 들면 환자에게 “추위를 느낍니까?” → “머리가 아픕니까?” 등의 질문을 통해 얻어 어떤 병에 걸렸을지 판단하는 것이죠.
저런 식으로 인공지능을 구현한다면 생각할 수 있는 조건의 조합이 거의 무한대일 테고 컴퓨터는 사람이 미리 입력해 놓은 조건문들을 벗어난 어떠한 판단도 내리지 못하겠죠. 지능이라고 부르기에도 민망한 수준입니다. 그나마 감기 환자를 판단하는 규칙은 복잡해도 컴퓨터에게 미리 프로그래밍해 놓을 수 있지만, 다음 그림과 같이 왼쪽 글자가 a이고 오른쪽 글자가 h인지를 컴퓨터에게 설명할 방법이 없습니다
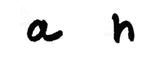
h를 예를 들어 볼까요? 위 그림처럼 왼쪽에 수직으로 선을 하나 긋고 오른쪽에서 위로 올라갔다가 다시 내려오는 포물선을 하나 붙이면 h라고 컴퓨터에게 설명할까요? 그럼 이건 어떨까요?

왼쪽 선이 수직이 아니라 오른쪽으로 약간 비스듬하게 기울었네요. 그런데 이것도 분명 h죠. 또 이건 어떨까요?

이번에는 수직선의 오른편에 비스듬한 N자가 붙어 있는 모양이네요. 그런데 이것도 h입니다. 사람들은 이 손글씨 알파벳을 보면 0.000….초 만에 h인 걸 알아보지만 어떤 규칙을 통해 h라고 아는지는 스스로도 모릅니다. 그러니 당연히 컴퓨터에게도 알려 줄 수 없는 것이죠.
4. 해결사로 등장한 머신러닝! 데이터로 돌파하다
이제 연구자들은 겸손해졌습니다. 지능을 인공적으로 만든다는 일이 얼마나 어려운 일인지 깨닫게 되었습니다. 우리는 지금 시점에서 딥러닝을 통해 저런 손글씨 알파벳쯤이야 컴퓨터가 충분히 판단한다는 걸 이미 알고 있지만, 당시엔 이 문제를 어떻게 돌파했을까요?
바로 “머신러닝(machine learning)”이었습니다. 여기서 ‘머신’은 컴퓨터라고 생각하면 되고, ‘러닝’은 어떤 규칙을 스스로 학습한다는 의미입니다. 컴퓨터가 스스로 배우는 것이죠. 무엇을 통해서? 바로 데이터를 통해서 배웁니다. 애초에 컴퓨터에게 어떠한 판단을 내릴 수 있는 모든 규칙을 가르치는 것은 불가능했으므로, 대신 “정답”이 붙어 있는 많은 데이터를 컴퓨터에게 던져 주고 스스로 학습하라고 명령하면 어떨까? 하는 생각에서 머신러닝은 시작되었습니다.
예를 들어 감기를 판단하는 사례로 설명해봅시다.

출처 : 보건복지부 & 대한의학회
그림에서 왼쪽은 감기 증상이고 오른쪽은 기관지염이라고 하는군요. 이걸 익숙한 엑셀 데이터로 표현해봅시다.

이런 데이터들이 아주 많다면 컴퓨터는 변수들이 어떤 조합을 구성하면 감기환자인지, 기관지염환자인지 스스로 규칙을 만들 수 있습니다.이런 가정을 해볼까요. 만약 어떤 병원에서 이 세상에 존재했고, 존재하며, 존재할 수 있는 모든 감기 환자와 기관지염 환자 데이터를 갖고 있고 이 데이터를 컴퓨터에 저장해 놓고 규칙을 만든다면 어떤 환자라도 정확하게 병명을 판단할 수 있습니다.
왜냐하면 새로운 환자는 반드시 갖고 있는 데이터에 존재하는 사례 중 하나일 것이므로 방대한 데이터 중에서 같은 사례를 찾기만 하면 되니까요. 그런데 현실에서 그런 가정은 불가능하죠. 보통 우리가 확보할 수 있는 데이터는 전체의 일부분일 뿐입니다. 아무튼 존재하는 데이터로 컴퓨터가 어떤 조건의 조합이면 감기환자이거나 기관지염 환자인지 규칙을 학습했다고 가정합시다.
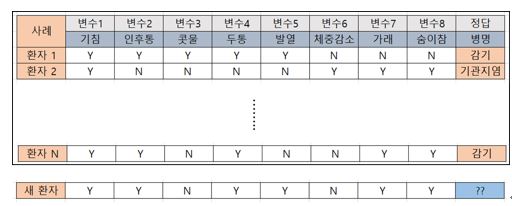
그런데 갑자기 기존에 없던 조건을 갖춘 새 환자가 병원에 찾아옵니다. 과거 데이터에 같은 사례가 없었으니 이제 컴퓨터는 기존에 있던 데이터를 이용해 새 환자의 병명을 추론해야 합니다. 어떻게 추론할까요? 간단합니다. 새환자와 비슷한 과거 사례를 찾아서 그 환자들의 병명이 새로운환자의 병명이라고 결론 내리면 됩니다. 100% 정확하지는 않겠지만 어차피 인간도 실수를 하니까 어느 정도 이상의 정답률만 보이면 나름 인공지능이라고 부를 만합니다.
아마도 이 부분에서 일부 사람들은 머신러닝 그거 별거 아니네? 라고 생각할지 모르겠습니다. 그런데 그게 결코 간단하지가 않습니다. 왜 그런지 한번 보죠.
5. 불규칙하게 분포하는 데이터 분류의 어려움
병명을 추론하는 문제를 n차원 공간에서 데이터의 정답을 분류하는 문제로 바꿔봅시다. 위의 감기 예에서 하나의 변수는 좌표축에서 하나의 차원이 됩니다. 아래 그림은 설명을 위해 단순화시켰는데, 그림에서 노란색 원이 감기, 초록색 원이 기관지염이라고 합시다.
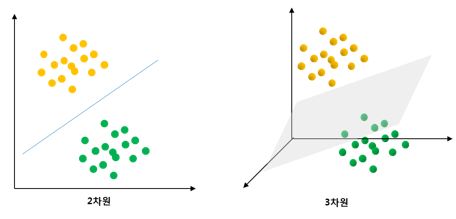
보통 같은 병명의 환자들은 각 증상(변수)이 비슷하니 n차원 공간에서 비슷한 위치에 뭉쳐 있겠죠. 이제 이런 감기환자와 기관지염 환자를 잘 구분할 수 있는 어떤 규칙을 만들어 놓습니다. 시각적으로 표현하면 왼쪽 그림의 파란색 선이나 오른쪽 그림의 회색 평면이 될 것입니다.그림으로 설명하기 위해 선과 면으로 표현되었지만 보통은 어떤 수식 또는 어떤 분기 절차를 떠올리면 됩니다.
이렇게 규칙을 만들어 놓고 새로운 환자(사례)의 변수들이 입력되면 새 환자가 보이는 변수의 값에 따라 n차원 공간에서 어디인가 위치하게 되겠죠. 그럼 새환자의 n차원 공간상에서의 위치가 선이나 평면을 경계로 어디에 속하는지 보고 병명을 추론하면 됩니다.
하지만 현실은 그렇게 아름답지 않습니다. 감기환자나 기관지염 환자들이 저렇게 깨끗하게 분류가 안된다는 것이죠. 현실에서도 감기환자인 듯한데 기관지염 환자이거나 기관지염 환자처럼 보이는데 그냥 감기 환자여서 오진하는 사례가 생기기도 합니다.
아래 그림을 볼까요. 빨간색 세모와 파란색 네모는 분류가 잘 안됩니다. 그렇기 때문에 위의 예처럼 단순한 직선이나 곡선으로는 이것들을 거의 정확하게 분류할 수 없습니다. 기존 데이터를 잘 분류할 수 없으니 새로운 사례가 입력되면 버벅됩니다. 버벅되면 인공지능이 아니죠. 게다가 아래 그림은 2차원이지만 데이터의 변수가 많아 차원이 높아지면 기존 데이터를 잘 분류하는 규칙을 만드는 것은 훨씬 어려운 문제가 됩니다.
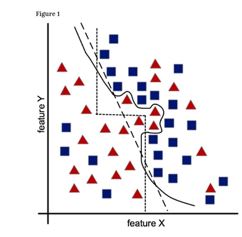
(출처: https://www.nature.com/articles/s41598-017-04281-9)
6. 머신러닝의 한계를 넘어, 딥러닝의 등장
현실적으로 어려움이 있지만 어쨌든 인공지능 연구자들은 머신러닝이 그나마 인공지능을 구현하는 길이라는 믿음으로 꾸준히 연구를 진행합니다. 오랜 시간 동안 연구자들은 기존의 더티(dirty)한 데이터를 잘 분류하는 규칙을 만들기 위해 여러 가지 방법들(선형, 비선형회귀, 로지스틱회귀, 의사결정트리, 신경망, 서포트벡터머신, 앙상블 기법 등)을 고민했고 이런 것들이 모두 딥러닝의 이웃이라고 볼 수 있습니다.
이렇게 다양한 방법들이 도토리 키재기 식으로 수십 년간 경쟁해 오다가 이렇게 딥러닝이 등장하자마자 이웃들을 자신의 능력치로 압살합니다. 그리고 그때까지도 인공지능 그게 되겠어? 라고 팔짱끼고 앉아 부정적이었던 사람들의 우려를 씻어내고 인공지능 개발을 선도하는 큰 형님의 역할을 맡게 됩니다.
지금까지 인공지능과 머신러닝, 딥러닝의 등장과 특징을 간단한 사례를 들어 살펴봤습니다. "인공지능이 뭐고 머신러닝이 뭔지 이제 대충알겠어, 그런데 딥러닝이 왜 그렇게 대단한건데?" 라고 생각한 분들이 있다면 일단은 성공인 것 같습니다. 다음 편에는 딥러닝을 본격적으로 해부해보겠습니다.
다음글
'인공지능 참고서' 카테고리의 다른 글
| 데이터 과학을 시작하려는 분들께 (0) | 2022.11.23 |
|---|---|
| 의사결정나무(decision tree) (0) | 2022.04.15 |
| 실체가 손에 잡히는 딥러닝(3) “이것만은 꼭 알아두자! 딥러닝의 꽃 - 가중치, 편향, 활성화 함수, 역전파” (0) | 2022.03.10 |
| 실체가 손에 잡히는 딥러닝(2) “인간의 뇌를 모방한 신경망, 그리고 딥러닝” (0) | 2022.03.09 |




댓글