선형회귀분석 밑바닥부터 이해하기
관련글 상관관계와 상관계수 1. 들어가며 연속형 변수 x, y의 관계는 상관관계(correlation) 분석을 통해 2가지 사실을 알 수 있다. 관계의 방향 관계의 강도 보통 관계의 방향은 그래프를 그려 확인
diseny.tistory.com
1. 들어가며
회귀분석에서는 결과변수가 연속형 변수이었지만 결과변수가 범주형 변수일 때도 있다. 아래 표는 공부 시간, 시험 성적, 합격 여부(합격 : 1, 불합격 : 0) 데이터이다.
| 공부시간 | 시험성적 | 합격여부 |
| 1 | 25 | 0 |
| 1 | 26 | 0 |
| ………….. | ||
| 1 | 27 | 0 |
| 2 | 30 | 0 |
| 2 | 31 | 0 |
| ………….. | ||
| 9 | 100 | 1 |
| 9 | 99 | 1 |
아래 <그림 1>의 왼쪽 그래프는 결과 변수인 시험 성적이 연속형 변수이고 0부터 100까지 여러 범위에 걸쳐 분포하지만 오른쪽 그림은 결과 변수가 범주형 변수라서 값이 0, 1뿐이다.

시험성적과 합격/불합격 여부의 변동성을 설명하기 위해 공부 시간 데이터를 고려하면 <그림 2>의 왼쪽 그림처럼 시험 성적을 예측하거나 성적의 변동성을 설명할 수 있다. 왼쪽 그림에서 공부 시간이 증가할 수록 성적이 향상되는 관계가 보인다. 한편, 오른쪽 그림에서는 공부 시간 데이터로 합격/불합격을 예측하거나 설명할 수 있다. 공부 시간이 작을 때는 불합격, 공부 시간이 많을 때는 합격에 분포한다.
문제는 이런 관계를 추정하기 위해 어떤 모델을 적용하느냐?이다.

2. 회귀모델 적합
<그림 3>의 왼쪽을 보면 선형 모델이 데이터에 적합된다. 반면 오른쪽 그림을 보면 데이터의 분포 형태가 선형이 될 수 없다. 또한 Y값이 해석불가이다. <그림 3>처럼 공부 시간이 5시간일 때 Y는 0.5이다. 0.5는 해석할 수 없는 결과변수다. Y는 합격(1)과 불합격(0) 둘 만 존재한다. 절반합격이라는 값은 존재할 수 없다. 따라서 결과변수가 범주형일때는 일반적인 선형 회귀 모델을 적용할 수 없다.

3. 선형회귀모델의 문제점 해결
이 문제를 해결하기 위해 결과변수인 Y를 합격/불합격이 아니라 합격할 확률(불합격할 확률)로 바꾸면 어떨까? 그러면 공부시간 5일 때 Y의 값 0.5는 합격(불합격)할 확률이다. Y를 합격여부가 아니라 합격 확률로 바꾸려면 위의 표를 다음과 같이 바꿔 생각할 수 있다.
| 시간 | 성적 | 합격 | 불합격 | 총인원 | 합격확률 |
| 0 | 25 | 1 | 17 | 18 | 0.06 |
| 1 | 30 | 1 | 15 | 16 | 0.06 |
| 2 | 40 | 1 | 14 | 15 | 0.07 |
| 3 | 50 | 3 | 20 | 23 | 0.13 |
| 4 | 75 | 5 | 5 | 10 | 0.50 |
| 5 | 70 | 8 | 3 | 11 | 0.73 |
| 6 | 85 | 8 | 1 | 9 | 0.89 |
| 7 | 90 | 9 | 1 | 10 | 0.90 |
| 8 | 100 | 9 | 1 | 10 | 0.90 |
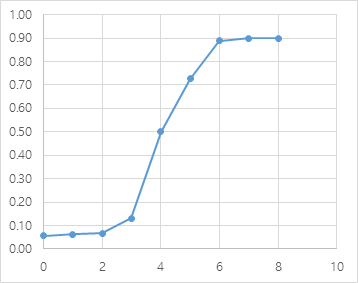
위의 표에서 X를 공부시간 Y를 합격 확률로 그래프를 그리면 <그림 4>가 된다. 이제 Y값을 해석할 수는 있게 되었다.
4. 로지스틱회귀 모델 적합
그러나 여전히 공부시간(X)과 합격확률(Y) 관계를 선형 모델로 설명하기에는 적합해 보이지 않는다. <그림 4> 그래프를 유심히 보면 공부시간 5시간을 기준으로 확률이 급격히 변하며 공부시간이 4시간 이하거나 7시간 이상에서는 합격률 변화가 크지 않는다.
데이터의 분포가 비스듬하게 누운 S자 비슷하게 생겼기 때문에 선형이 아니라 S자 형태의 곡선을 데이터에 적합시키는 것이 적당해 보인다. 이렇게 S자 모양의 그래프를 수식으로 나타내면 <그림 5>의 오른쪽 그림과 같다.

우리는 왼쪽 직선 그래프를 표현한 수식에는 익숙하다. 직선을 의미하는 Y=ax+b에서 a와 b를 알면 여러 대안적인 선 중에서 가장 적합한 직선을 결정할 수 있다. 반면 오른쪽 S자 모양 그래프의 수식이 익숙하지는 않겠지만 이런 모양의 그래프를 표현하는 수식이 이와 같다고 받아들이고 시작하자.
식에서 e는 자연로그의 밑으로서 대략 2.71정도의 값이다. 이 수식에서도 a와 b를 알면 좌표계에서 구체적인 S자 형태의 그래프를 그릴 수 있다. a, b가 달라지면 모양은 비슷하지만 기울기나 위치가 조금 다른 S곡선(점선)을 그릴 수 있다는 사실을 보여주고 있다.
선형 회귀에서 데이터를 가장 잘 대표하는 직선 모델의 a, b를 결정하기 위해 최소제곱법을 이용했지만 데이터를 가장 잘 대표하는 S곡선의 a, b를 결정하기 위해서는 최대가능도추정법(MLE : Maximum Likelihood Estimation)을 이용한다. 최대가능도추정법은 로그 미분 등의 수학 지식이 필요하고 수식 전개가 다소 복잡해 다음 글에서는 기본 원리에 대해 이해하기 쉽게 설명한다.
로지스틱회귀와 친구되기(2)
이전글 로지스틱회귀와 친구되기(1) 관련글 선형회귀분석 밑바닥부터 이해하기 관련글 상관관계와 상관계수 1. 들어가며 연속형 변수 x, y의 관계는 상관관계(correlation) 분석을 통해 2가지 사실을
diseny.tistory.com
'통계 이론' 카테고리의 다른 글
| 대격변 AI 시대, 한 권으로 끝내는 데이터과학, 확률, 통계, AI 특강 (0) | 2024.05.22 |
|---|---|
| 상관계수의 크기에 대한 감 잡기 (0) | 2024.04.22 |
| 로지스틱회귀와 친구되기(2) (0) | 2022.04.26 |
| 분산분석(ANOVA) 이해하는 가장 좋은 방법(3) (0) | 2022.04.25 |
| 분산분석(ANOVA) 이해하는 가장 좋은 방법(2) (4) | 2022.04.22 |
| 분산분석(ANOVA) 이해하는 가장 좋은 방법(1) (4) | 2022.04.22 |
| t-test 밑바닥부터 이해하기 (2) | 2022.04.21 |




댓글