관련글
상관관계와 상관계수
1. 들어가며 연속형 변수 x, y의 관계는 상관관계(correlation) 분석을 통해 2가지 사실을 알 수 있다. 관계의 방향 관계의 강도 보통 관계의 방향은 그래프를 그려 확인하고, 관계의 강도는 그래프로
diseny.tistory.com
평균의로의 회귀
1. 들어가며 노벨 경제학상을 수상하기도 했던 심리학자 대니얼 카너먼(Daniel Kahneman)은 명저 '생각에 관한 생각(Thinking, Fast and Slow)'에서 평균으로의 회귀 현상에 대한 좋은 사례를 소개합니다.
diseny.tistory.com
1. 들어가며
두 연속형 변수 X, Y에서 X가 변함에 따라 Y가 어떻게 변하는지 분석한다면 Y는 결과변수(반응변수)로 부르고 X는 설명변수(독립변수)로 부른다. 회귀 분석은 결과변수와 설명변수의 관계를 선형(linear)으로 분석하는 방법이다. 설명변수가 하나일 때는 단순회귀분석 둘 이상일 때는 다중회귀라고 부른다.
2. 상관관계와 회귀분석
상관계수(관련글 : 상관관계와 상관계수) 를 통해 두 연속형 변수의
- 관계 유무
- 관계 방향성
- 관계 강도
파악하는 방법을 살펴보았다. 회귀분석을 이용하면 상관분석에 비해 더 많은 정보를 얻을 수 있다. 구체적으로 다음 2가지다.
- ① X(설명변수)를 이용해 Y(결과변수)를 추정할 수 있다.
- ② X를 이용해 Y를(Y의 변동성) 설명할 수 있다.
②의 의미를 조금 더 생각해보자. Y의 값이 개별 데이터가 모두 다를 때, 즉 데이터에 변동성이 있을 때 이 변동성을 X를 통해 설명할 수 있다는 의미이다. <그림 1>을 살펴보자.

왼쪽 그래프에서 보이는 것처럼 성적에 차이가 있다. X가 세 학생의 머리 크기라고 하면 학생의 머리 크기 차이는 작다. 게다가 머리크기 차이 마저도 세 학생의 성적 증가 방향과 일치 하지 않는다. 즉 철이는 영희보다 머리가 작지만 성적이 높고 민주는 영희보다 머리가 크지만 성적은 높다. 차이의 방향성이 일관적이지 않은 것이다.
반면 X가 공부시간이면 성적 차이는 공부시간 차이와 유사한 패턴을 보인다. 세 학생의 성적 차이를 세 학생의 공부시간차이로 설명할 수 있다. 어떤 현상(성적 차이)을 설명할 때 주어진 데이터(공부 시간)를 이용하는 것이다.
만약 성적, 머리 크기, 공부 시간이라는 데이터만 있다면 머리 크기는 성적의 변동성을 설명할 수 없지만 공부 시간은 어느정도 설명할 수 있다. 이렇게 한 변수의 변동성을 다른 변수의 변동성으로 설명하는 분석 방법이 회귀 모델이다. X와 Y의 관계를 설명할 수 있다면 X를 통해 Y를 추정할 수 있으므로 사실상 ①과 ②는 같은 의미이다. 단지 어디에 초점을 두느냐가 다르다.
3. 선형회귀모델
<그림 2>는 X, Y 데이터의 선형 회귀 모델을 나타낸 것이다. 빨간 대각선은 일차 방정식 Y = aX + b로 표현할 수 있고 이 함수가 선형 회귀 모델이다. 회귀 모델에서 X의 값이 주어지면 Y의 값을 예측할 수 있고 X앞에 붙은 a(기울기)를 통해 X가 한 단위 변할 때 Y가 얼마나 변하는지 추정할 수 있다.
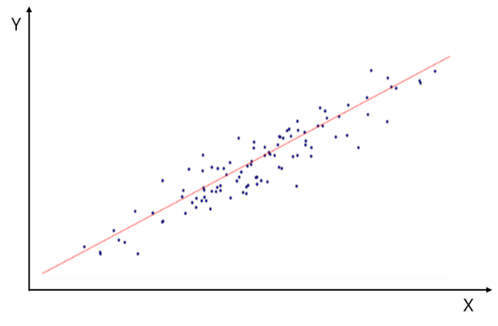
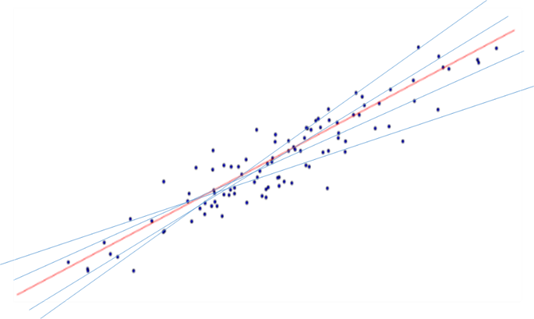
그런데 <그림 2>처럼 X, Y의 관계를 하나의 대각선으로 표현할 수 있다면 그 선은 어떻게 결정할까요? 그림 <3>와 같이 X, Y의 데이터 분포에서 무수히 많은 대각선을 그을 수 있다. 결론부터 말하자면 여러 대각선 중에서 X, Y 데이터에 가장 적합한(fitted), 다른 말로 X, Y의 관계를 가장 잘 대표하는 선을 선택한다. 가장 적합한 선(모델)을 선택하는 일반적인 방법으로 최소제곱법(OLS : ordinary least squares)이 있다.
4. 최적 선형회귀모델 선택
<그림 4>와 같이 회귀선으로 예측한 값과 실제 데이터의 값에 차이가 있을 때 이 값을 잔차(residuals)라고 하고 각 잔차 값을 제곱하고 모두 더한 것을 잔차제곱합(RSS : Residual sum of squares)이라고 한다.
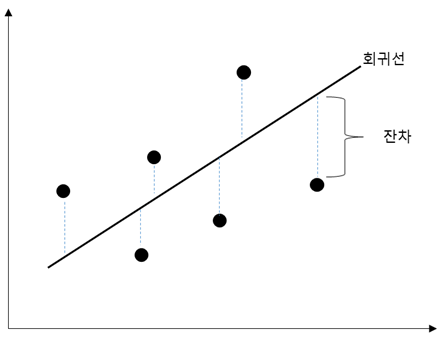
잔차제곱합이 작다는 것은 실제 값과 회귀 모델로 예측한 값의 차이가 작다는 의미이며, X, Y의 관계를 오차가 적도록 가장 잘 대표한다고 볼 수 있다. 이렇게 잔차제곱합이 가장 작은 선을 선형 회귀 모델로 선택한다. 회귀 모델(대각선)을 결정한다는 말은 Y = aX + b라는 회귀선의 a, b를 결정한다는 말이다.
5. 회귀모델 진단
회귀모델을 만들었다면 모델의 통계적 유의성에 대해 따져보아야 한다. 먼저 통계적 유의성에 대해 살펴보자. 표본 데이터의 X, Y 관계가 모집단에서도 동일한지 추정하려고 할 때를 생각해보자. <그림 5>에서 왼쪽은 모집단에서 X, Y의 관계이며 오른쪽은 모집단에서 추출한 표본 데이터의 x, y 관계이다.
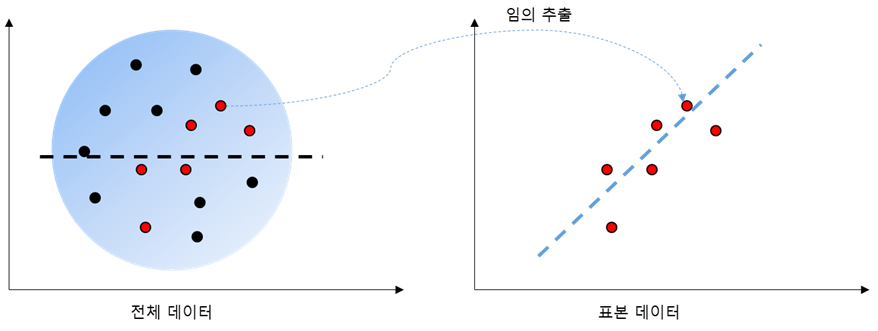
왼쪽 모집단에서 X, Y의 관계는 상관계수가 0에 가깝고 오른쪽 표본에서 x, y 관계는 뚜렷한 양의 상관관계가 보인다. 무작위 추출이라면 이렇게 편향적으로 추출될 확률은 매우 낮지만 어쨌든 가능성이 0%는 아니다. 이 경우 오른쪽 표본으로 구한 회귀 모델로 모집단을 추정하면 오류가 발생할 것이다. 그런데 우리가 갖고 있는 데이터는 오른쪽에 있는 표본 데이터이고 왼쪽의 모집단 데이터는 모른다. 모집단을 모르기 때문에 현재 모델이 오류가 있는지는 알 수 없고 단지 어느 정도의 확률로 모델에 오류가 있을 가능성을 열어 둘 뿐이다.
회귀식으로 표현하자면 Y = aX + b에서 a = 0 일 가능성을 따져보는 것이다. 회귀식에서 a는 회귀계수이며 회귀계수는 t검정을 통해 통계적 유의성을 검정한다.
6. 회귀모델의 성능
일반적으로 회귀모델의 성능은 결정계수(R^2)으로 측정한다. 결정계수는 아래 관련글을 참고하기 바란다.
결정계수(R^2)의 이해
1. 들어가며 선형회귀분석에서 모델의 적합도를 판단할 때, 결정계수(R^2)값이 중요한 판단 근거가 된다. 결정계수(R squared)의 의미에 대해 살펴보자. 2. 모델의 의미 예를 들어 <그림 1>과 같이 A ~ G
diseny.tistory.com
회귀진단
관련글 선형회귀분석 밑바닥부터 이해하기 선형회귀분석 밑바닥부터 이해하기 관련글 상관관계와 상관계수 1. 들어가며 두 연속형 변수 X, Y에서 X가 변함에 따라 Y가 어떻게 변하는지 분석한다
diseny.tistory.com
로지스틱회귀와 친구되기(1)
관련글 선형회귀분석 밑바닥부터 이해하기 관련글 상관관계와 상관계수 1. 들어가며 연속형 변수 x, y의 관계는 상관관계(correlation) 분석을 통해 2가지 사실을 알 수 있다. 관계의 방향 관계의 강
diseny.tistory.com
'통계 이론' 카테고리의 다른 글
| 확률, 확률변수 그리고 확률분포 (2) | 2022.04.18 |
|---|---|
| 이상값과 영향력 있는 관측값 탐지 (2) | 2022.04.14 |
| 회귀진단 (0) | 2022.04.13 |
| 상관관계와 상관계수 (0) | 2022.03.31 |
| 확인적 요인분석(CFA : Confirmatory Factor Analysis) (0) | 2022.03.30 |
| 혼동행렬(confusion matrix) (2) | 2022.03.30 |
| 표준편차와 추론 통계 (0) | 2022.03.24 |




댓글