# naver search confirm
# markdown number and equation
'데이터분석' 태그의 글 목록
//google adsense
 R 중복값을 갖는 행(row) 데이터 제거
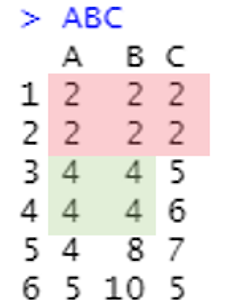
이전글 R 결측값 시각화 1. 들어가며 일반적으로 summary(데이터프레임) 명령어로 각 변수의 결측값(Na's) 수를 확인할 수 있지만 변수별 결측값 수 또는 비율을 간편하게 시각화할 수 있는 패키지가 있다. 그러한 기능을 제 diseny.tistory.com 1. 들어가며 데이터 분석과정에서 중복된 값을 제거해야 할 일이 종종있다. 이런 작업을 수행하는 방법은 다양하지만 dplyr 패키지의 distinct 함수를 이용한 방법을 소개한다. 2. 샘플 데이터 생성 library(dplyr) A = c(2,2,4,4,4,5) B = c(2,2,4,4,8,10) C = c(2,2,5,6,7,5) ABC = data.frame(A,B,C) ABC 코드를 실행하면 다음과 같은 데이터 프레임을 얻을 수 있다. ..
2022. 5. 16.
R 중복값을 갖는 행(row) 데이터 제거
이전글 R 결측값 시각화 1. 들어가며 일반적으로 summary(데이터프레임) 명령어로 각 변수의 결측값(Na's) 수를 확인할 수 있지만 변수별 결측값 수 또는 비율을 간편하게 시각화할 수 있는 패키지가 있다. 그러한 기능을 제 diseny.tistory.com 1. 들어가며 데이터 분석과정에서 중복된 값을 제거해야 할 일이 종종있다. 이런 작업을 수행하는 방법은 다양하지만 dplyr 패키지의 distinct 함수를 이용한 방법을 소개한다. 2. 샘플 데이터 생성 library(dplyr) A = c(2,2,4,4,4,5) B = c(2,2,4,4,8,10) C = c(2,2,5,6,7,5) ABC = data.frame(A,B,C) ABC 코드를 실행하면 다음과 같은 데이터 프레임을 얻을 수 있다. ..
2022. 5. 16.



