1. 들어가며
세 집단 이상의 비교에는 아노바(ANOVA)를 이용하는데 ANOVA는 Analysis of Variance의 줄임말이며 우리말로는 분산분석이다. 두 집단이든 세 집단이든 각 집단의 평균을 비교해, 어디가 제일 높고 낮은지 확인하면 충분하다. 그런데 표본 데이터에서의 차이가 통계적으로 유의한지 검증해야 표본의 결과를 일반화할 수 있는데 이때 분산을 이용해 통계적 유의성을 검증하기 때문에 분산분석이라고 부른다.
두 집단 비교에서는 평균 차이를 이용했지만 세 집단 이상에서는 분산으로 통계적 유의성을 확인한다는 것에 유의해야 한다.
2. 두 집단의 평균 차이를 여러 번 하지 못하는 이유
A, B, C 세 집단이 있다면 A : B, A : C, B : C를 각각 비교하면 되지 않겠냐고 생각할 수 있다.
예를 들어 A>B, B>C이면 A>B>C라고 생각할 수도 있다.
그런데 A>B는 어디까지나 표본에서 그렇다는 것이고 모집단으로 확장했을 때는 A>B가 틀릴 가능성이 5%존재한다. 마찬가지로 B>C라고 추정할 때도 5%의 오차가 존재한다.
표본으로 모집단을 추정할 때는 오류 가능성을 5% 이내로 하자는 사회적 합의가 있는데 A>B>C는 개별적으로 추정할 때 한번씩 5%의 오류 가능성이 있으므로 이를 더하면 이미 추정의 오류 가능성이 5%를 넘어간다. 5%가 절대적인 기준은 아니지만 커뮤니케이션의 수단으로서 통계를 사용한다면 규약은 지키는 것이 바람직하고 너무 큰 오류 가능성은 추론의 정당성도 훼손시켜 사용할 수 없게 된다.
3. 분산분석의 의미
분산으로 세 집단 이상의 차이를 비교한다는 개념이 다소 이해가 안될 수 있다. 왜 평균이 아니라 분산으로 비교하는가?
이에 대해서는 아래 관련글에서 충분히 설명해 놓았으므로 참고하기 바란다.
분산으로 평균차이 검증하기(분산분석)
1. 들어가며 두 표본의 평균 차이를 검증하는 T분석 방법을 배운 뒤, 세 집단(표본) 이상을 분석하려면 분산분석(ANOVA)을 해야 한다고 배운다. 왜 평균의 차이를 분산으로 분석하는거지? 라는 의문
diseny.tistory.com
4. 분산의 분할
분산은 (1)집단간 분산과 (2)집단내 분산으로 구분할 수 있다.
● 집단내 분산 : 각 집단을 구성하는 개별 데이터간에 변동성이 있는데 이 변동성의 평균을 구하면 집단내 분산이다.
● 집단간 분산 : 또한 각 집단끼리도 평균의 차이, 즉 변동성이 있는데 이 집단간 변동성의 평균이 집단간 분산이다.
실험 데이터에서는 집단을 처치로 바꿔 처치간 분산, 처치내 분산이라고 표현한다.
만약 A, B, C의 평균이 다르다면 그 이유는 집단(처치)이 다른 것이 표면적인 이유이다. 반면 집단내에서 발생하는 개별 데이터의 변동성은 무슨 이유 때문일까? 현재로서는 모른다. 이유를 모르기 때문에 에러 또는 우연이라고 하자. 이제 아래 식과 같이 집단간 분산과 집단내 분산을 비교한다고 생각해 보자.
F = 집단간 분산 / 집단내 분산
예를 들어 집단간 분산이 2인데 집단내 분산이 10이라고 하자. 즉,
F = 2 / 10
집단이 다르다는 이유로 분산이 2만큼 있는데 이 2는 우연히 발생할 수 있는 분산(집단내 분산) 10 보다 작다. 그렇다면 집단이 달라서 발생하는 분산이라기보다는 그냥 우연히 발생할 수 있는 분산의 범위 내에 있으므로 집단이 다르다는 원인이 변동성의 이유, 근거가 되기에 부족하다.
반대로 집단간 분산이 10인데 집단내 분산이 2라고 하자.
F = 10 / 2
그러면 우연히 발생할 수 있는 분산보다 집단간 분산이 5배가 더 크다. 따라서 우연히 발생할 수 있는 분산이외에도 집단이 달라서 발생한 분산이 섞여 있다는 이야기가 되며 결론적으로 집단간 차이, 즉 변동성이 발생했다는 논리로 이어진다.
5. 통계적 유의성
위의 F값(집단간 분산/집단내 분산)은 F분포를 따른다고 알려져 있다.
F분포 어디에 쓰일까?
※이전글 카이제곱 분포 관련글 확률, 확률변수 그리고 확률분포 1. 들어가며 통계학은 기술통계와 추론통계로 구분되는데, 기술통계와 추론통계를 연결해주는 것이 확률분포이다. 그런데 확률
diseny.tistory.com
만약 세 모 집단의 평균이 동일하다면(귀무가설) 집단간의 평균 차이는 없고 따라서 집단간 분산 값은 작을 것이다. 집단간 분산 값이 작으므로 F식 정의에 의해
F = 집단간 분산 / 집단내 분산
F값은 1보다 작거나 1보다 크더라도 작은 숫자일 것이고 이런 작은 값들은 F분포 상에서 발생할 확률이 아주 클 것이다.
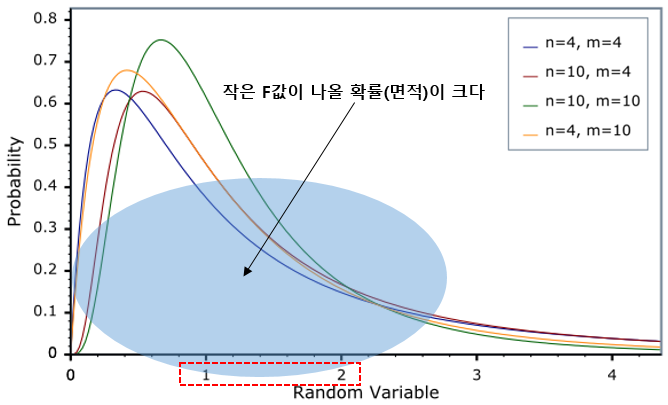
반대로 표본에서 집단간 분산이 집단내 분산보다 훨씬 크고 그 결과 큰 숫자의 F 값이 나왔다면 모집단에 대한 가정이 맞다는 전제하에 F분포상에서 발생할 확률이 아주 작을 것이고 희박한 확률을 가진 값이 나왔기 때문에 모집단에서 평균이 같다는 가정을 기각해야 한다.
이제 다음글에서 구체적으로 데이터를 이용해 분산분석을 계산하는 방법을 따라가보자. 작은 데이터로 한번 계산을 해보면 분산분석의 의미를 더 잘 이해할 수 있다.
분산분석(ANOVA) 이해하는 가장 좋은 방법(2)
※ 이전글 분산분석(ANOVA) 이해하는 가장 좋은 방법(1) 1. 들어가며 세 집단 이상의 비교에는 아노바(ANOVA)를 이용하는데 ANOVA는 Analysis of Variance의 줄임말이며 우리말로는 분산분석이다. 두 집단이
diseny.tistory.com
예측 모델의 재현도(Recall)와 정밀도(Precision)
1. 들어가며 머신러닝(AI 포함) 모델의 성능은 논문을 출간할 때 SOTA(Sate of the Art) 값이 중요하긴 하지만 현업에서 적용하고 운영할 때는 다양한 이유로 무조건 높은 값을 추구할 수 만은 없다.
diseny.tistory.com
'통계 이론' 카테고리의 다른 글
| 로지스틱회귀와 친구되기(1) (0) | 2022.04.26 |
|---|---|
| 분산분석(ANOVA) 이해하는 가장 좋은 방법(3) (0) | 2022.04.25 |
| 분산분석(ANOVA) 이해하는 가장 좋은 방법(2) (4) | 2022.04.22 |
| t-test 밑바닥부터 이해하기 (2) | 2022.04.21 |
| F분포 어디에 쓰일까? (5) | 2022.04.21 |
| 카이제곱 분포 이해하기 (4) | 2022.04.19 |
| 확률, 확률변수 그리고 확률분포 (2) | 2022.04.18 |




댓글