※이전글
카이제곱 분포
관련글 확률, 확률변수 그리고 확률분포 1. 들어가며 통계학은 기술통계와 추론통계로 구분되는데, 기술통계와 추론통계를 연결해주는 것이 확률분포이다. 그런데 확률분포를 이해하기 위해서
diseny.tistory.com
1. 들어가며
당연한 말이지만 F분포는 F값의 확률분포라는 의미다. 그럼 F값이 무엇인지부터 알아야 한다. 2개의 확률변수 X, Y에 대해 각 확률변수를 다음과 같이 정의한다.

위의 식1, 식2에서 X, Y는 카이제곱 값을 자유도로 나눈 형태다.
※관련글
자유도(Degree of Freedom)에서 자유로워 지기
1. 들어가며 자유도는 통계학을 공부하다 보면 아마 제일 처음 만나는 알쏭달쏭한 개념이다. 최초로 등장하는 시기는 표본분산을 구할 때다. 표본으로 모분산을 추정할 때는 표본의 개수(n)가 아
diseny.tistory.com
이때 F값은 X와 Y의 비율로 정의한다.

2. F값 분해하기
이 시점에서 아마도 X, Y, F를 왜 저렇게 정의하고 도대체 무슨 의미가 있는 것인지 궁금해진다. 마지막 단계에서 의문점이 해결되므로 일단은 설명을 차근차근 따라가보자. 위의 <식 1>에서 X의 분자인 카이제곱값만 따로 떼어 살펴보자.

위 식에서 확률변수 X값들이 같은 모집단에서 추출되었다고 가정하면, 즉 평균(μ)과 표준편차(σ)가 같다면 평균(μ)과 표준편차(σ)를 아래첨자로 구분할 필요가 없으므로 <식 3>은 <식 4> 표현할 수 있다.

계속 비슷한 형태의 개별 값을 더하므로 시그마를 이용해 표현하다. Y의 분자도 마찬가지로 생각할 수 있다. 그러면 X, Y를 구분하기 위해 식을 고쳐 써 보자.
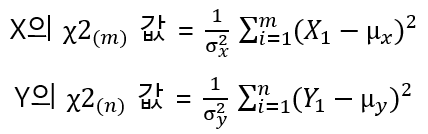
위의 각 식을 F값을 정의하는 식에 대입하면 아래와 같다.

이제 거의 다 왔다. 마지막으로 한번 더 가정하자. X와 Y가 동일한 모집단에서 추출한 확률변수라면, 즉 평균(μ)과 표준편차(σ)가 같다면 평균(μ)과 표준편차(σ)를 아래첨자로 구분할 필요가 없으므로 F식은 다음과 같이 변형된다.
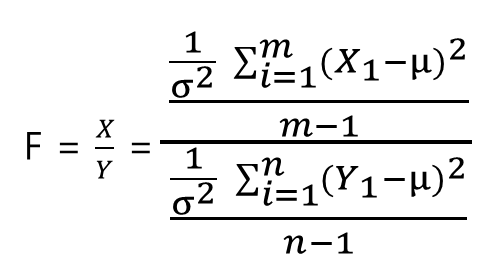
위 식에서 분자와 분모에 있는 1/σ^2를 약분할 수 있으므로 식은 최종적으로 아래와 같이 정리할 수 있다.

3. F값 이해하기
위의 식에서 분자와 분모를 뚫어지게 쳐다 보자. 분자와 분모는 바로 X, Y 데이터의 분산입니다. 정확하게는 말하자면 불편분산인데 불편분산은 분모가 자유도라는 일반적인 분산식과의 차이점이다.
최종적으로 식을 정리하면 결국 F는 동일한 모집단에서 추출한 두 확률변수 집단의 분산 비율이다. F는 비율(나눗셈)이므로 음수 값은 없고 양수만 있다. 카이제곱분포와 마찬가지로 자유도에 따라 모양이 달라지며 모양을 결정하기 위해 두 개의 자유도가 필요하다.
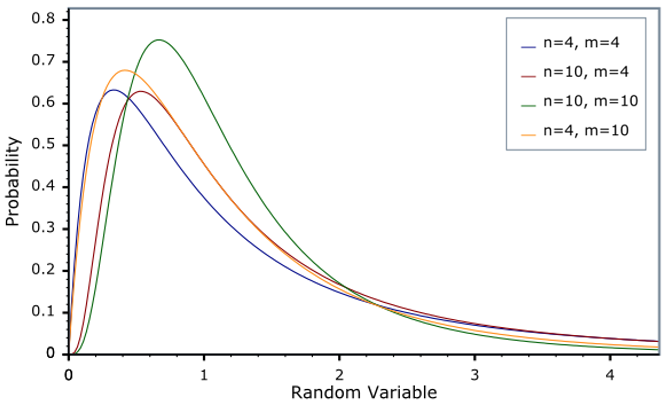
4. F분포의 활용
그럼 F분포는 어디에 쓰일까? 위에서 수식을 정리할 때 계속 데이터가 “동일한 모집단에서 추출된 확률변수라는 가정”을 이용했다. 이 말은 두 개의 데이터 집단이 동일한 모집단에서 추출되었다면 추출한 데이터로부터 계산한 F값이 F분포를 따라야 한다는 말이다. 만약 F분포를 안 따른다면 두 개의 집단은 동일한 모집단에서 추출된 것이 아니라고 생각하는 것이 통계적 사고다. 결국 여러 데이터 집단이 동일한지 아닌지, 구체적으로는 평균이 같은지 아닌지를 검정하기 위해(분산분석) F분포를 이용할 수 있다.
'통계 이론' 카테고리의 다른 글
| 분산분석(ANOVA) 이해하는 가장 좋은 방법(2) (4) | 2022.04.22 |
|---|---|
| 분산분석(ANOVA) 이해하는 가장 좋은 방법(1) (4) | 2022.04.22 |
| t-test 밑바닥부터 이해하기 (4) | 2022.04.21 |
| 카이제곱 분포 이해하기 (6) | 2022.04.19 |
| 확률, 확률변수 그리고 확률분포 (2) | 2022.04.18 |
| 이상값과 영향력 있는 관측값 탐지 (2) | 2022.04.14 |
| 회귀진단 (0) | 2022.04.13 |




댓글