관련글
가설검증과 1종 오류
1. 들어가며 가설을 검증한다는 말은 검증하는 사람(분석가)이 명확한 근거를 갖고 있거나 정답을 알고 있다는 뉘앙스를 가진다. 그러나 검증이라는 표현보다는 결단을 내린다는 말이 사실에 더
diseny.tistory.com
가설검증과 2종오류
지난글 가설검증과 1종 오류 1. 들어가며 지난 글에서 가설검증과 1종오류에 대해 다뤘다. 이제 2종 오류에 대해 생각해보자. 1종 오류는 귀무가설이 맞는데도 귀무가설을 기각하는 오류다. 반변,
diseny.tistory.com
1. 들어가며
통계학은 기술통계(descriptive statistics)와 추론 통계(inference statistics)로 나뉜다. 표본(sample) 데이터의 특징만 분석하는 것이 기술통계라면 표본 데이터에서 얻은 결과를 이용해 모집단의 특징(모수 : 평균, 분산 등)을 추정하는 단계까지 가는 것이 추론 통계이다. 추론 통계의 구체적인 한 형태가 가설검증인데, 이번 글에서는 추론 통계의 중요한 계산 값이 되는 표준편차에 대해 알아보자.
2. 표준편차와 임의 추출
<그림 1>은 A, B 데이터 집한을 직선상의 빈도로 표현한 그래프이다. 두 데이터의 평균은 모두 3.7이지만 두 데이터의 분포가 다르다. 즉 평균은 동일한데 표준편차가 다른 데이터이다.
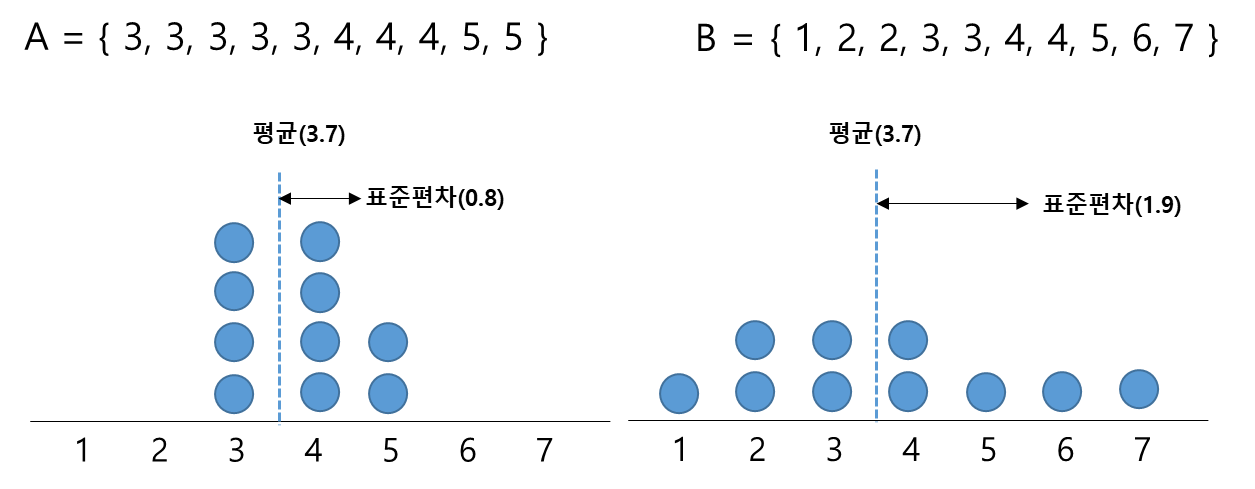
이때 A, B 두 데이터 집합에서 하나의 숫자 데이터를 임의 추출한다고 했을 때, 평균 3.7에 가까운 숫자를 뽑을 확률은 A, B 중 어디가 더 클까? 구체적인 계산 없이도 직관적으로 A에서 평균 3.7에 가까운 숫자 하나를 뽑을 확률이 더 크게 느껴진다. 왜 그럴까?
3. 모집단 추론과 표준편차
이제 <그림 2>에서는 5개의 데이터를 임의 추출해서 그 평균을 구했을 때, 그 평균이 전체 데이터 평균 3.7에 어느 쪽이 더 가까울지 생각해보자. 당연히 이번에도 왼쪽(A)에서 뽑인 5개의 데이터 평균이 3.7에 더 가까울 것 같은 느낌적인 느낌이 든다.
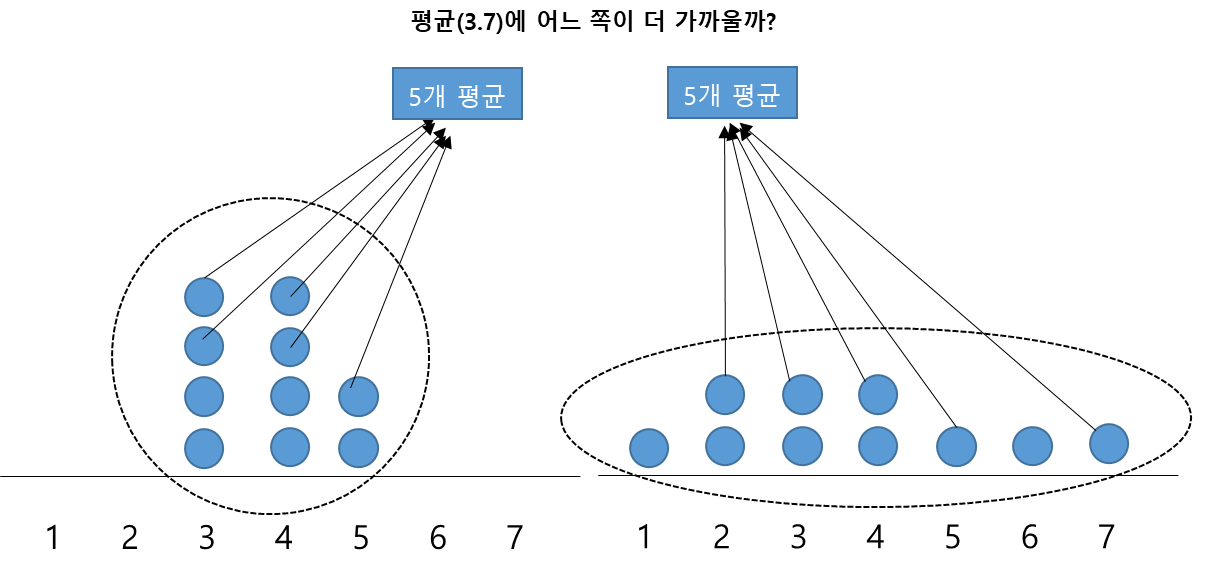
이제 전체 데이터 10개를 모집단이라고 하고 임의 추출된 5개의 데이터를 표본이라고 생각해보자. 모집단(10개)의 평균이 3.7인지는 이제 모른다고 가정하고 A, B에서 뽑힌 표본 5개의 평균으로 모집단 평균을 추정한다고 생각해 보자. 당연히 모집단 평균과 표본으로 추정한 평균은 차이(오차)가 발생할 것이다.
그런데 A, B 어느 쪽에서 추출된 표본의 평균이 모집단 평균과 차이가 많이 날까? 같은 느낌으로 이번에도 A쪽이 더 오차가 작을 것 같다.
이 모든 느낌의 밑바탕에는 각 표본의 표준편차 값이 중요하게 작동한다. 표본의 표준편차가 작을 수록 미지의 모집단 모수를 추정할 때 더 오차가 작을 것이라고 예상하는 것이다. 따라서 모든 추론 통계의 복잡한 수식에는 표본의 표준편차가 매우 중요한 역할을 하게 된다.
4. 결론 및 추신
여기에서 중요한 사실은, 지금까지 표준편차로 추론 통계의 오차의 크고 작음을 예상할 때, 그 예상이 맞으려면 표본이 무작위로 뽑혔다는 중요한 가정이 전제되어야 한다. 그래야 표본이 모집단을 닮았다는 가정이 성립하므로 지금까지 이야기한 논리가 합리적일 수 있다.
'통계 이론' 카테고리의 다른 글
| 상관관계와 상관계수 (0) | 2022.03.31 |
|---|---|
| 확인적 요인분석(CFA : Confirmatory Factor Analysis) (0) | 2022.03.30 |
| 혼동행렬(confusion matrix) (2) | 2022.03.30 |
| ROC 곡선 아주 쉽게 이해하기 (4) | 2022.03.21 |
| 결정계수(R^2)의 이해 (0) | 2022.03.08 |
| 가설검증과 2종오류 (0) | 2022.03.06 |
| 분산으로 평균차이 검증하기(분산분석) (2) | 2022.03.02 |




댓글