1. 들어가며
이분형 예측 통계(머신러닝) 모델은 예측의 성능을 측정하는 기준이 필요하다. 이때 가장 대표적으로 이용되는 측정 지표가 혼동행렬표이다. 혼동행렬표로부터 모델의 성능을 측정하는 4가지 값을 얻을 수 있다. 하나씩 살펴보자
2. 혼동행렬표
아래 <그림 1>은 혼동행렬표를 나타낸다. 왼쪽 그림의 2X2행렬표에서 [1,1]셀은 A라고 예측했는데 실제 데이터도 A인 것을 의미하고 [2,2]셀은 B라고 예측했는데 실제 데이터도 B인 경우다. 즉 O표는 예측값과 실제값이 일치하는 경우다. 반대로 X표는 예측값과 실제값이 다른 경우다. 따라서 O셀의 숫자가 많을 수록 그 모델은 성능이 좋다고 말할 수 있다.
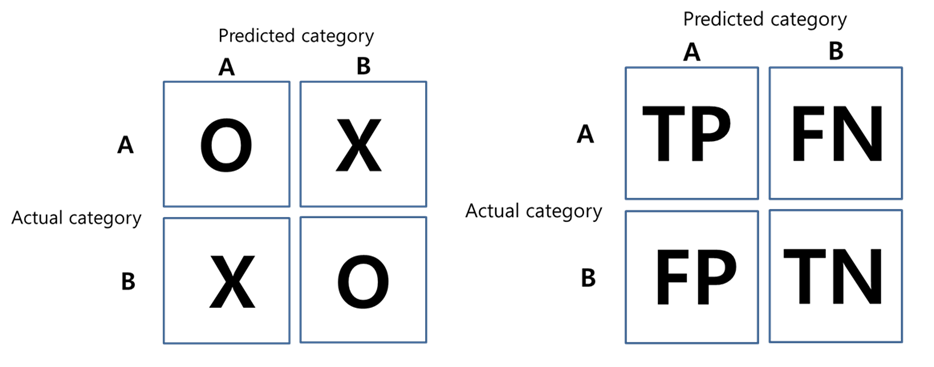
이때 관심범주라는 개념을 알아야 한다. 관심범주란 분석가가 더 관심이 있는 범주를 의미한다. 모델이 A를 더 잘 예측하는 것이 중요한지 B를 더 잘 예측하는지 중요한지는 분석가의 의도에 달렸다. 일단 위의 경우 관심 범주를 A라고 하면 오른쪽 TP, FN, FP, TN의 의미가 분명해진다.
관심범주가 A일 때,
- True Positive(TP) : 관심 범주를 정확하게 분류함
- True Negative(TN) : 관심 범주 아닌 것을 정확하게 분류함
- False Positive(FP) : 관심 범주로 잘못 분류함
- False Negative(FN) : 관심 범주가 아닌 것으로 잘못 분류함
당연히 TP, TN의 숫자가 많을 수록 좋은 모델이지만 TP와 TN중 어디에 더 초점을 둘 것이냐의 문제는 있다.
3. 4가지 지표
이제 혼동행렬표로부터 모델의 성능을 측정하는 4가지 성능 지표에 대해 알아보자. 4가지 지표는 아래와 같다.
- 정확도(Accuracy)
- 재현도(Recall)
- 정밀도(Precision)
- F 스코어
하나씩 개념을 살펴보자.
- 정확도(Accuracy)
예측 모형의 전체적인 정확도를 평가한다. 예를 들어 관심범주가 암환자라고 한다면 암환자를 암환자로 예측하고, 정상인을 정상인으로 예측한 비율을 의미한다. <그림 2>에서처럼 구성된 혼동행렬표를 근거로 정확도를 계산하면 92%가 나온다.
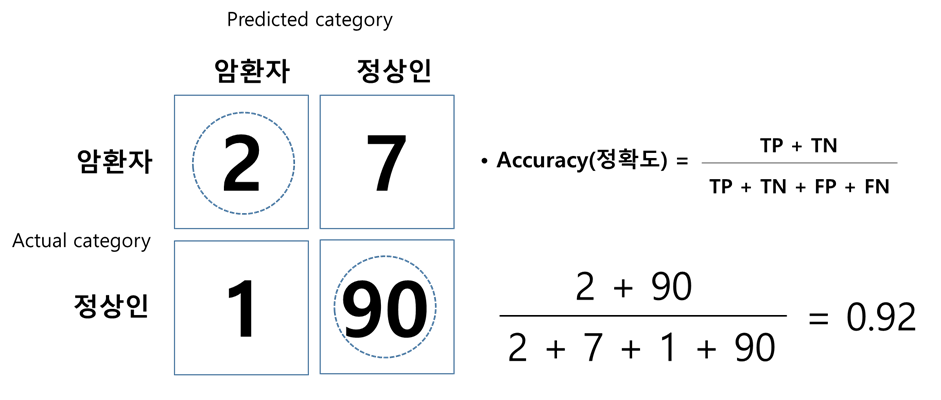
그런데 위 사례에서는 문제가 있다. 비록 모델의 정확도가 92%로써 굉장히 높지만 암환자만 따로 떼어 놓고 보면 성능이 별로 좋지 못하다. 즉 암환자가 실제로 9명(2+7) 존재하는데 2명만 암환자로 예측했다. 모델의 전체적인 정확도는 높지만 정작 모델의 관심범주는 절반도 예측하지 못했다. 이런 이유 때문에 또 다른 모델 성능 평가 수치가 필요하다.
- 재현도(Recall)
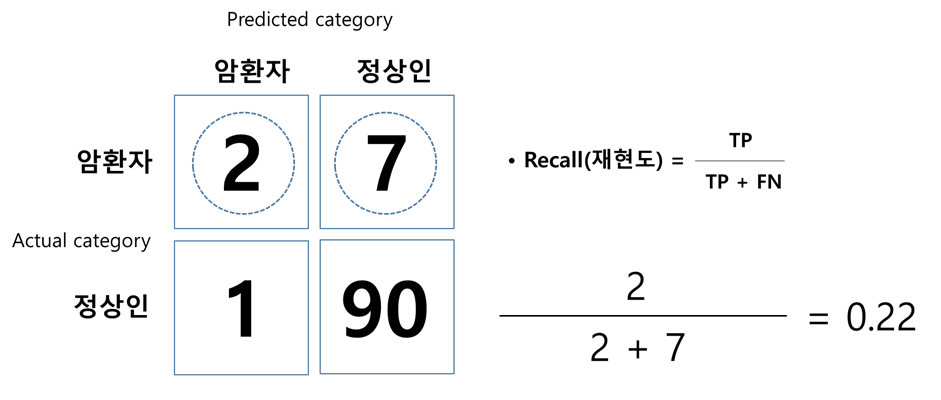
예측 모델이 실제 데이터에서 존재하는 암환자(관심범주) 중 몇 개를 암환자로 예측했는지에 대한 수치다. <그림 3> 경우 재현도는 22%에 지나지 않는다. 만약 암환자의 경우처럼 관심범주 예측이 굉장히 중요한 범주형 예측 모델에서는 재현도 값이 실질적으로 더 의미 있는 모델 성능 값이다.
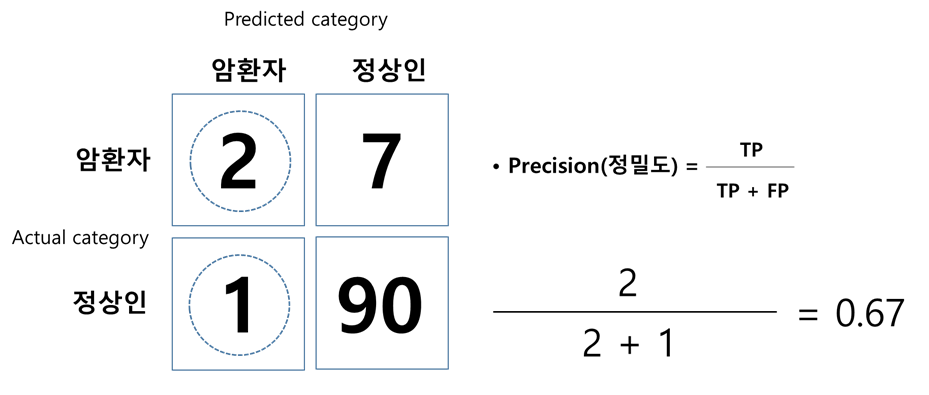
- 정밀도(Precision)
예측의 질(quality)에 대한 수치이다. <그림 4>예측 모델은 총 3명이 암환자라고 예측했고, 그 중에 2명을 제대로 맞췄으니까 약 67%의 정밀도를 갖는다. 비록 암환자 예측을 깐깐하게 했지만 예측 자체의 정확도는 약간 높다고 볼 수 있다.
- F 스코어
결국 좋은 예측 모델은 재현도와 정밀도가 동시에 좋아야 한다. 어느 한쪽의 값을 높이기 위해서 다른 한쪽 수치의 질을 희생시켜서는 안될 것이다. 이렇게 재현도와 정밀도의 성능을 동시에 확인하기 위해 F 스코어 값을 이용한다.
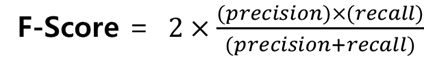
F 스코어는 재현도와 정밀도가 둘다 높으면 F 스코어도 높고, 어느 한쪽이 낮거나 둘 다 낮으면 F스코어가 낮아지도록 고안된 수식이다.
4. 결론
이상의 논의를 요약하자면, 범주형 변수 예측 모형의 성능은 혼동행렬표 상의 정확도, 재현도, 정밀도, F 스코어로 측정하고, 예측하려는 변수의 특징과 상황에 따라 네 가지 성능 평가 수치를 적절하게 활용해야한다. 혼동행렬표이외에도 모델의 성능을 평가하는 지표로서 ROC 곡선도 유명하다. ROC 곡선은 아래 관련글을 참고하기 바란다.
ROC 곡선 아주 쉽게 이해하기
1. 들어가며 통계 또는 머신러닝 모델을 만든 후에는 모델의 성능을 측정해야 한다. 대표적인 성능 측정 방법으로 혼동행렬과 ROC곡선이 있다. 혼동행렬표가 이해하기 쉬운데 반해 ROC 곡선은 직
diseny.tistory.com
'통계 이론' 카테고리의 다른 글
| 선형회귀분석 밑바닥부터 이해하기 (0) | 2022.04.01 |
|---|---|
| 상관관계와 상관계수 (0) | 2022.03.31 |
| 확인적 요인분석(CFA : Confirmatory Factor Analysis) (0) | 2022.03.30 |
| 표준편차와 추론 통계 (2) | 2022.03.24 |
| ROC 곡선 아주 쉽게 이해하기 (4) | 2022.03.21 |
| 결정계수(R^2)의 이해 (0) | 2022.03.08 |
| 가설검증과 2종오류 (0) | 2022.03.06 |




댓글